小前言:
近日很幸運的參加了中研院資訊科學研究所廖弘源所長在科技島舉辦的線上演講,收穫很多,也了解在YOLOv4到YOLOv7發表論文之間,除了有YOLOv5之外還有PP-YOLO、YOLOR、YOLOX、YOLOv6等方法。因為這次30天的挑戰,秉持想要了解目前YOLO系列網路的技術內容,因此這邊會調整一下預先設定的目錄,在介紹YOLOv6以前先介紹PP-YOLO、YOLOR以及YOLOX,讓系列文章更加完整。
PP-YOLO: An Effective and Efficient Implementation of Object Detector
Xiang Long, Kaipeng Deng, Guanzhong Wang, Yang Zhang, Qingqing Dang, Yuan Gao, Hui Shen, Jianguo Ren, Shumin Han, Errui Ding, Shilei Wen.
- 作者來自Baidu Inc.
- 在YOLOv3的基礎上進行改良。
- 論文標題命名的PP,是因為該技術是實作在百度的深度學習框架PaddlePaddle。
-
探討更多的Bag of Freebies方法(Tricks)。
- 沒有使用基因演算法(NAS)找尋最佳超參數。
整體網路架構
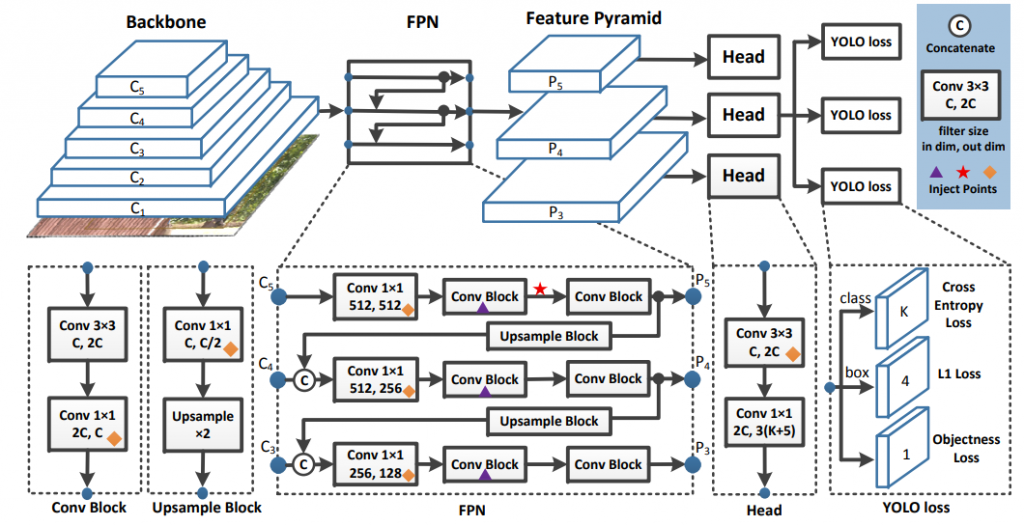
Backbone:
- 將YOLOv3的DarkNet-53改成ResNet50-vd,因為作者認為ResNet已經被廣泛研究以及使用,因此ResNet的變體網路已經得到很好的優化。
- 這邊作者發現單純改用ResNet50-vd作為Backbone會造成準確度下降,因此有添加一些變體卷積網路層(Deformable Convolution layers)。
- DCN(Deformable Convolutional Network):
- 不會劇烈增加模型參數量,但加太多層會增加Inference時間。
Neck:
Head:
- Classification: Cross-Entropy Loss。
- Localization: L1 Loss。
- Objectness loss : 判斷是否有物件。
Tricks:
-
Batch size設大一點讓模型更加穩定。
-
參數訓練方式使用EMA(Exponential Moving Average),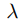 為衰變變數,論文設為0.9998。採用這個訓練方式有機會提升最終的訓練結果。
為衰變變數,論文設為0.9998。採用這個訓練方式有機會提升最終的訓練結果。
-
DropBlock:移除一部分舉行範圍的影像資訊。

- 作者只增加DropBlock技術在FPN網路當中(架構途當中的紫色三角形標示),若添加在Backbone會造成準確度下降。
-
Grid Sensitive:
- 求Bounding Box中心點x,y座標的時候:
-
原本YOLOv3:
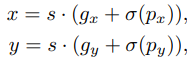
- 問題:因為值計算出來很難落在
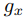 或是
或是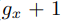 ,這將導致模型很難預測剛好Bounding Box中心點落在Grid cell邊界的物件。
,這將導致模型很難預測剛好Bounding Box中心點落在Grid cell邊界的物件。
-
PP-YOLO:
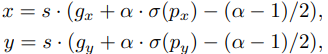
- 改成這樣可以解決上述問題,且FLOPs增加的很少,可以被忽略。
-
Matrix NMS: 比傳統NMS更快,並且不會影響模型效能。
-
CoordConv:
- 添加額外的座標Channel。
- 讓模型學會
- 平移不變性:物件座標在哪個位置都要能夠辨識。
- 平移相依性:物件偵測需要知道物件在影像當中的確切位置。
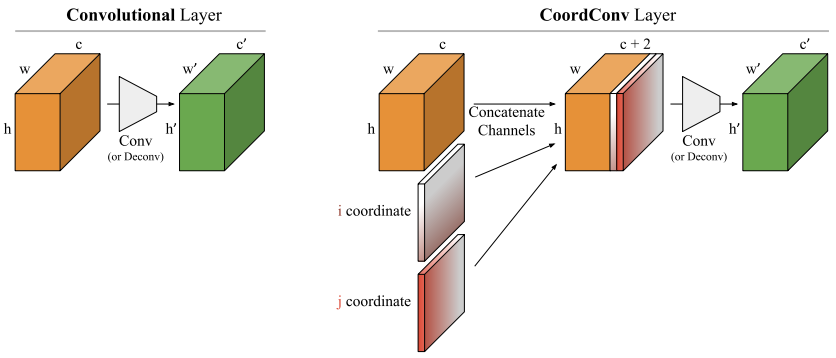
- 添加後參數量會變多,因此避免影響模型效能,只添加在FPN當中以及Detection Head當中(架構圖當中的菱形標示)。
-
SPP(Spatial Pyramid Pooling):
- YOLOv4已經有採用,因此細節可以參見YOLOv4-上篇中的說明。
- PP-YOLO也有採用(架構圖中的星形標示)。
-
使用預訓練模型: PP-YOLO採用ImageNet distilled ResNet50-vd預訓練模型,得到更好的detection結果。
其他提升準確度方法
實驗結果
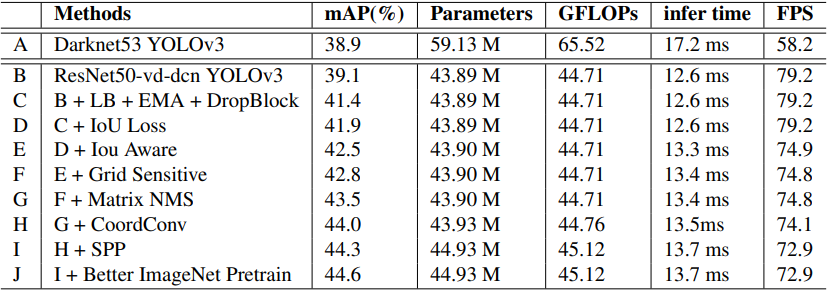
- 添加各種Trick的消融實驗:
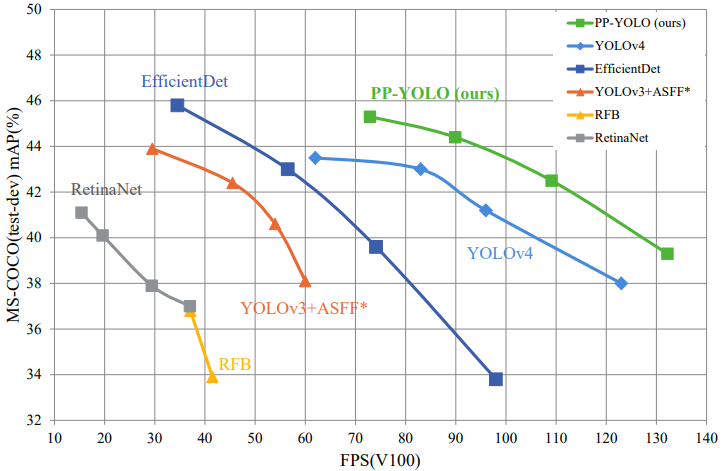
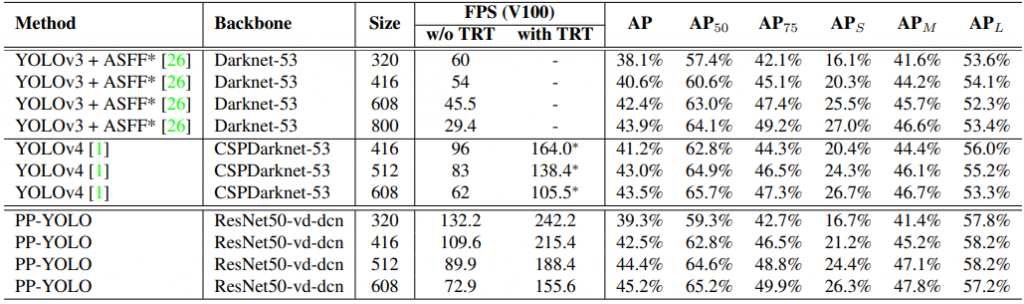
- 與YOLO系列網路的比較:
文章使用之圖片擷取自該篇論文


 iThome鐵人賽
iThome鐵人賽